what other block replacement technique can be used and is proved to be the ideal
In computing, enshroud algorithms (likewise oftentimes called cache replacement algorithms or cache replacement policies) are optimizing instructions, or algorithms, that a computer programme or a hardware-maintained structure can employ in order to manage a enshroud of information stored on the computer. Caching improves operation by keeping recent or frequently-used data items in retentivity locations that are faster or computationally cheaper to access than normal memory stores. When the enshroud is total, the algorithm must choose which items to discard to make room for the new ones.
Overview [edit]
The average memory reference time is[1]

where
- = miss ratio = 1 - (striking ratio)
- = fourth dimension to brand a main memory access when there is a miss (or, with multi-level enshroud, average retentiveness reference time for the next-lower enshroud)
- = the latency: the time to reference the cache (should be the same for hits and misses)
- = diverse secondary effects, such equally queuing effects in multiprocessor systems




There are two primary figures of merit of a enshroud: The latency, and the hit rate. At that place are also a number of secondary factors affecting enshroud operation.[ane]
The "hit ratio" of a enshroud describes how oft a searched-for item is actually establish in the cache. More than efficient replacement policies proceed runway of more usage information in gild to improve the hit rate (for a given cache size).
The "latency" of a enshroud describes how long subsequently requesting a desired particular the cache tin return that particular (when at that place is a hitting). Faster replacement strategies typically keep rails of less usage information—or, in the case of direct-mapped enshroud, no data—to reduce the amount of time required to update that information.
Each replacement strategy is a compromise betwixt hit charge per unit and latency.
Hit rate measurements are typically performed on criterion applications. The actual hit ratio varies widely from one application to another. In particular, video and sound streaming applications frequently take a hitting ratio close to zero, because each bit of information in the stream is read once for the first time (a compulsory miss), used, and and then never read or written over again. Even worse, many cache algorithms (in detail, LRU) let this streaming data to fill the cache, pushing out of the cache data that volition be used over again soon (enshroud pollution).[2]
Other things to consider:
- Items with different toll: keep items that are expensive to obtain, e.thousand. those that have a long fourth dimension to become.
- Items taking upward more cache: If items accept different sizes, the cache may want to discard a large item to store several smaller ones.
- Items that expire with time: Some caches proceed information that expires (eastward.g. a news enshroud, a DNS cache, or a web browser cache). The computer may discard items because they are expired. Depending on the size of the cache no further caching algorithm to discard items may exist necessary.
Diverse algorithms likewise exist to maintain cache coherency. This applies only to situation where multiple independent caches are used for the same data (for instance multiple database servers updating the single shared data file).
Policies [edit]
Bélády'due south algorithm [edit]
The most efficient caching algorithm would be to always discard the data that volition not be needed for the longest time in the future. This optimal result is referred to as Bélády's optimal algorithm/simply optimal replacement policy or the clairvoyant algorithm. Since it is generally impossible to predict how far in the future information volition be needed, this is mostly not implementable in practice. The practical minimum can be calculated only later on experimentation, and one tin compare the effectiveness of the actually chosen cache algorithm.
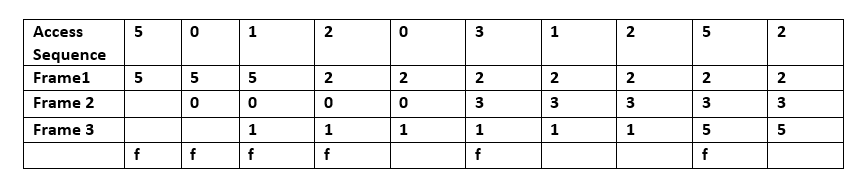
At the moment when a folio error occurs, some set of pages is in memory. In the example, the sequence of 'five', '0', '1' is accessed past Frame 1, Frame 2, Frame three respectively. So when 'two' is accessed, information technology replaces value '5', which is in frame 1 since information technology predicts that value 'five' is not going to be accessed in the near future. Because a existent-life general purpose operating organisation cannot really predict when 'v' will be accessed, Bélády'southward Algorithm cannot exist implemented on such a system.
Random replacement (RR) [edit]
Randomly selects a candidate particular and discards it to make space when necessary. This algorithm does not crave keeping any information about the access history. For its simplicity, it has been used in ARM processors.[3] Information technology admits efficient stochastic simulation.[4]
Simple queue-based policies [edit]
First in starting time out (FIFO) [edit]
Using this algorithm the cache behaves in the same way as a FIFO queue. The enshroud evicts the blocks in the order they were added, without any regard to how often or how many times they were accessed before.
Last in first out (LIFO) or First in last out (FILO) [edit]
Using this algorithm the cache behaves in the same style as a stack and opposite way as a FIFO queue. The enshroud evicts the block added nearly recently first without whatsoever regard to how ofttimes or how many times it was accessed before.
Unproblematic recency-based policies [edit]
Least recently used (LRU) [edit]
Discards the least recently used items starting time. This algorithm requires keeping track of what was used when, which is expensive if 1 wants to make sure the algorithm e'er discards the least recently used particular. General implementations of this technique require keeping "age bits" for cache-lines and track the "Least Recently Used" enshroud-line based on age-bits. In such an implementation, every time a cache-line is used, the age of all other cache-lines changes. LRU is really a family unit of caching algorithms with members including 2Q by Theodore Johnson and Dennis Shasha,[5] and LRU/K by Pat O'Neil, Betty O'Neil and Gerhard Weikum.[6]
The access sequence for the beneath example is A B C D Eastward D F.

In the above example one time A B C D gets installed in the blocks with sequence numbers (Increment i for each new Access) and when East is accessed, it is a miss and it needs to be installed in one of the blocks. According to the LRU Algorithm, since A has the everyman Rank(A(0)), East will replace A.
In the 2nd to last step, D is accessed and therefore the sequence number is updated.
Finally, F is accessed taking the place of B which had the lowest Rank(B(i)) at the moment.
Time aware least recently used (TLRU) [edit]
The Time aware Least Recently Used (TLRU)[7] is a variant of LRU designed for the situation where the stored contents in cache accept a valid life time. The algorithm is suitable in network cache applications, such as Data-centric networking (ICN), Content Delivery Networks (CDNs) and distributed networks in general. TLRU introduces a new term: TTU (Time to Use). TTU is a time postage of a content/page which stipulates the usability fourth dimension for the content based on the locality of the content and the content publisher announcement. Owing to this locality based time stamp, TTU provides more than control to the local administrator to regulate in network storage. In the TLRU algorithm, when a piece of content arrives, a cache node calculates the local TTU value based on the TTU value assigned by the content publisher. The local TTU value is calculated by using a locally defined function. Once the local TTU value is calculated the replacement of content is performed on a subset of the full content stored in enshroud node. The TLRU ensures that less popular and small life content should be replaced with the incoming content.
Most recently used (MRU) [edit]
In contrast to Least Recently Used (LRU), MRU discards the most recently used items first. In findings presented at the 11th VLDB conference, Chou and DeWitt noted that "When a file is being repeatedly scanned in a [Looping Sequential] reference pattern, MRU is the best replacement algorithm."[8] Subsequently, other researchers presenting at the 22nd VLDB conference noted that for random access patterns and repeated scans over large datasets (sometimes known every bit cyclic access patterns) MRU cache algorithms have more hits than LRU due to their tendency to retain older information.[ix] MRU algorithms are well-nigh useful in situations where the older an item is, the more likely it is to be accessed.
The access sequence for the below case is A B C D E C D B.

Here, A B C D are placed in the cache every bit there is still space bachelor. At the fifth access E, we see that the block which held D is now replaced with Due east as this cake was used most recently. Another access to C and at the next admission to D, C is replaced every bit it was the block accessed merely earlier D and and so on.
Segmented LRU (SLRU) [edit]
SLRU cache is divided into 2 segments, a probationary segment and a protected segment. Lines in each segment are ordered from the nearly to the to the lowest degree recently accessed. Data from misses is added to the cache at the most recently accessed end of the probationary segment. Hits are removed from wherever they currently reside and added to the most recently accessed stop of the protected segment. Lines in the protected segment take thus been accessed at least twice. The protected segment is finite, so migration of a line from the probationary segment to the protected segment may force the migration of the LRU line in the protected segment to the virtually recently used (MRU) terminate of the probationary segment, giving this line another gamble to exist accessed earlier beingness replaced. The size limit on the protected segment is an SLRU parameter that varies co-ordinate to the I/O workload patterns. Whenever data must be discarded from the cache, lines are obtained from the LRU end of the probationary segment.[x]
LRU Approximations [edit]
LRU tin be prohibitively expensive in caches with college associativity. Applied hardware commonly employs an approximation to accomplish like performance at a much lower hardware cost.
Pseudo-LRU (PLRU) [edit]
For CPU caches with large associativity (mostly >4 means), the implementation cost of LRU becomes prohibitive. In many CPU caches, a scheme that near always discards ane of the least recently used items is sufficient, so many CPU designers choose a PLRU algorithm which merely needs one bit per enshroud item to piece of work. PLRU typically has a slightly worse miss ratio, has a slightly better latency, uses slightly less power than LRU and lower overheads compared to LRU.
The following example shows how Bits piece of work equally a binary tree of 1-bit pointers that point to the less recently used subtree. Following the pointer chain to the leaf node identifies the replacement candidate. Upon an access all pointers in the chain from the accessed way'southward leaf node to the root node are set to point to subtree that does not contain the accessed way.
The access sequence is A B C D E.

The principle here is simple to empathize if nosotros only look at the arrow pointers. When at that place is an access to a value, say 'A', and we cannot notice it in the enshroud, so we load it from memory and place information technology at the block where the arrows are currently pointing, going from meridian to bottom. After we have placed that cake we flip those same arrows so they point the opposite way. In the higher up case we see how 'A' was placed, followed past 'B', 'C and 'D'. Then every bit the cache became full 'Eastward' replaced 'A' because that was where the arrows were pointing at that time, and the arrows that led to 'A' were flipped to point in the opposite direction. The arrows then led to 'B', which volition be the cake replaced on the side by side enshroud miss.
CLOCK-Pro [edit]
LRU algorithm cannot exist directly implemented in the critical path of estimator systems, such as operating systems, due to its high overhead. An approximation of LRU, called CLOCK is ordinarily used for the implementation. Similarly, CLOCK-Pro is an approximation of LIRS for an low price implementation in systems.[11] CLOCK-Pro is under the bones CLOCK framework, but has three major distinct claim. First, CLOCK-Pro has three "clock hands" in contrast to a uncomplicated structure of CLOCK where only one "hand" is used. With the three hands, CLOCK-Pro is able to measure the reuse altitude of information accesses in an approximate way. 2d, all the merits of LIRS are retained, such as rapidly evicting one-time accessing and/or low locality information items. Tertiary, the complication of the CLOCK-Pro is same as that of CLOCK, thus it is piece of cake to implement at a low cost. The buffer enshroud replacement implementation in the electric current version of Linux is a combination of LRU and CLOCK-Pro.[12] [13]
Elementary frequency-based policies [edit]
Least-frequently used (LFU) [edit]
Counts how oft an item is needed. Those that are used least ofttimes are discarded first. This works very similar to LRU except that instead of storing the value of how recently a block was accessed, nosotros store the value of how many times it was accessed. And then of class while running an access sequence we will supplant a cake which was used fewest times from our cache. E.g., if A was used (accessed) 5 times and B was used iii times and others C and D were used x times each, we will supervene upon B.
Least frequent recently used (LFRU) [edit]
The Least Frequent Recently Used (LFRU)[14] cache replacement scheme combines the benefits of LFU and LRU schemes. LFRU is suitable for 'in network' cache applications, such as Data-axial networking (ICN), Content Delivery Networks (CDNs) and distributed networks in general. In LFRU, the enshroud is divided into two partitions called privileged and unprivileged partitions. The privileged partition can be defined as a protected segmentation. If content is highly popular, it is pushed into the privileged partition. Replacement of the privileged partitioning is done as follows: LFRU evicts content from the unprivileged partition, pushes content from privileged partition to unprivileged partition, and finally inserts new content into the privileged partitioning. In the higher up process the LRU is used for the privileged partition and an approximated LFU (ALFU) scheme is used for the unprivileged sectionalization, hence the abridgement LFRU.
The basic thought is to filter out the locally popular contents with ALFU scheme and push the popular contents to i of the privileged partition.
LFU with dynamic crumbling (LFUDA) [edit]
A variant chosen LFU with Dynamic Aging (LFUDA) that uses dynamic aging to accommodate shifts in the gear up of popular objects. It adds a cache historic period factor to the reference count when a new object is added to the cache or when an existing object is re-referenced. LFUDA increments the cache ages when evicting blocks by setting it to the evicted object's key value. Thus, the cache age is always less than or equal to the minimum central value in the cache.[15] Suppose when an object was frequently accessed in the past and now it becomes unpopular, it will remain in the cache for a long time thereby preventing the newly or less pop objects from replacing it. So this Dynamic aging is introduced to bring down the count of such objects thereby making them eligible for replacement. The advantage of LFUDA is information technology reduces the cache pollution acquired past LFU when cache sizes are very modest. When Cache sizes are large few replacement decisions are sufficient and cache pollution volition not be a problem.
RRIP-mode policies [edit]
RRIP-manner policies course the basis for many other cache replacement policies including Hawkeye[16] which won the CRC2 championship and was considered the most advanced cache replacement policy of it's time.
Re-Reference Interval Prediction (RRIP) [edit]
RRIP[17] is a very flexible policy proposed by Intel that attempts to provide practiced scan resistance while also allowing older cache lines that haven't been reused to be evicted. All cache lines have a prediction value called the RRPV (Re-Reference Prediction Value) that should correlate with when the line is expected to be reused. On insertion, this RRPV is usually loftier, so that if the line isn't reused before long, information technology will be evicted, this is done to prevent scans (big amounts of data that is used only once) from filling upward the cache. When a cache line is reused, this RRPV is prepare to goose egg, indicating that this line has been reused once, and is likely to be reused again.
On a cache miss, the line with the RRPV equal to the maximum possible RRPV is evicted (for case, with 3-bit values, the line with the RRPV of 2iii = 7 is evicted), if no lines have this value, all RRPVs in the set up are incremented past 1 until 1 reaches it. A tie breaker is needed, and commonly information technology'southward the first line on the left. This increment is needed to make sure that older lines are aged properly and will be evicted if they aren't reused.
Static RRIP (SRRIP) [edit]
SRRIP inserts lines with an RRPV value of maxRRIP. This means that a line that has just been inserted volition be the most probable to be evicted on a cache miss.
Bimodal RRIP (BRRIP) [edit]
SRRIP performs well in the normal example, but suffers when the working set is much larger than the cache size and causes cache thrashing, this is remedied by inserting lines with an RRPV value of maxRRPV well-nigh of time, and inserting lines with an RRPV value of maxRRPV - one randomly with a low probability. This causes some lines "stick" in the enshroud and help confronting thrashing.
However, BRRIP degrades performance on not thrashing accesses.
Dynamic RRIP (DRRIP) [edit]
SRRIP performs best when the working set is smaller than the cache size, while BRRIP performs all-time when the working set is larger than the cache size.
DRRIP[17] aims for the best of both worlds. It uses set dueling[18] to select whether to utilise SRRIP or BRRIP. It dedicates a few sets (typically 32) to but apply SRRIP and another few to but utilise BRRIP, and information technology uses a policy counter that monitors which of these sets performs better to make up one's mind which policy will exist used by the rest of the cache.
Enshroud replacement policies approximating Bélády'due south algorithm [edit]
Bélády'due south algorithm is the optimal cache replacement policy, only it requires knowledge of the time to come to adios lines that will be reused farthest in the future. Multiple replacement policies have been proposed that attempt to predict time to come reuse distances from past access patterns. Thus allowing them to approximate the optimal replacement policy. Some of the all-time performing cache replacement policies are ones that endeavour to imitate Bélády's algorithm.
Eagle [edit]
Hawkeye[sixteen] attempts to emulate Bélády'due south algorithm past using past accesses by a PC to predict whether the accesses it produces generate cache friendly accesses (accesses that get used after on) or cache averse accesses (don't get used later on).
It does this by sampling a number of the enshroud sets (that aren't aligned), it uses a history of length and emulates Bélády's algorithm on these accesses. This allows the policy to effigy out which lines should have been buried and which should not accept been cached.

This data allows information technology to predict whether an instruction is cache friendly or enshroud averse. This data is then fed into an RRIP, and means accesses from instructions that are cache friendly accept a lower RRPV value (likely to be evicted later on), and accesses from instructions that are enshroud balky have a college RRPV value (likely to be evicted sooner).
The RRIP backend is the part that does the actual eviction decisions. The sampled cache and OPT generator are merely used to gear up the initial RRPV value of the inserted cache lines.
Hawkeye won the CRC2 cache championship in 2017,[nineteen] beating all other enshroud replacement policies at the time.
Harmony[20] is an extension of Hawkeye that improves prefetching performance.
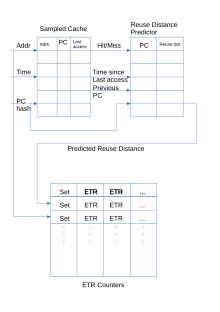
Block diagram of the Mockingjay cache replacement policy.
Mockingjay [edit]
Mockingjay[21] tries to improve upon Eagle in multiple ways. Get-go, it drops the binary prediction, allowing it more brand more fine grained decisions well-nigh which cache lines to adios. Second, information technology leaves the determination about which enshroud line to evict later on, afterwards more information is available.
Information technology achieves this past keeping a sampled enshroud of unique accesses, the PCs that produced them and their timestamps. When a line in the sampled cache gets accessed over again, the deviation in fourth dimension volition exist sent to the Reuse Distance Predictor, which uses Temporal Difference Learning,[22] where the new RDP vale will be incremented or decremented by a small number to compensate for outliers. The number is calculated as . Except when the value has not been initialized, in which case the observed reuse distance is inserted directly. If the sampled cache is full, and we demand to throw away a line, nosotros train the RDP that the PC that concluding accessed it produces streaming accesses.

On an admission or insertion, the Estimated Time of Reuse (ETR) for this line is updated to reverberate the predicted reuse distance. Every few accesses to the fix, decrement all the ETR counters of the set (which can fall into the negative, if not accesses by their estimated time of reuse).
On a cache miss, the line with the highest absolute ETR value is evicted (The line which is estimated to be reused farthest in the future, or has been estimated to be reused uttermost in the past and hasn't been reused).
Mockingjay achieves results that are very close to the optimal Bélády's algorithm, typically inside just a few percent operation difference.
Enshroud replacement policies using machine learning [edit]
Multiple cache replacement policies accept attempted to use perceptrons, markov chains or other types of auto learning to predict while line to evict.[23] [24]
Other enshroud replacement policies [edit]
Low inter-reference recency set up (LIRS) [edit]
LIRS is a page replacement algorithm with an improved performance over LRU and many other newer replacement algorithms. This is achieved past using reuse altitude every bit a metric for dynamically ranking accessed pages to make a replacement decision.[25] LIRS effectively address the limits of LRU by using recency to evaluate Inter-Reference Recency (IRR) for making a replacement decision.

In the to a higher place figure, "x" represents that a cake is accessed at time t. Suppose if cake A1 is accessed at fourth dimension 1 then Recency will become 0 since this is the first accessed block and IRR will be 1 since it predicts that A1 will be accessed again in time 3. In the fourth dimension 2 since A4 is accessed, the recency will go 0 for A4 and i for A1 considering A4 is the virtually recently accessed Object and IRR will get 4 and it will keep. At time 10, the LIRS algorithm will have ii sets LIR set = {A1, A2} and HIR set = {A3, A4, A5}. Now at time 10 if in that location is access to A4, miss occurs. LIRS algorithm volition now evict A5 instead of A2 considering of its largest recency.
Adaptive replacement enshroud (ARC) [edit]
Constantly balances between LRU and LFU, to amend the combined result.[26] ARC improves on SLRU past using information about recently evicted cache items to dynamically adjust the size of the protected segment and the probationary segment to make the all-time use of the available enshroud space. Adaptive replacement algorithm is explained with the case.[27]
AdaptiveClimb (AC) [edit]
Uses recent hit/miss to adapt the jump where in climb any hit switches the position one slot to the peak, and in LRU hit switches the position of the hit to the superlative. Thus, benefiting from the optimality of climb when the programme is in a stock-still scope, and the rapid adaption to a new scope, equally LRU does.[28] Also support cache sharing among cores by releasing extras when the references are to the pinnacle role of the cache.
Clock with adaptive replacement (CAR) [edit]
Combines the advantages of Adaptive Replacement Cache (ARC) and CLOCK. CAR has performance comparable to ARC, and substantially outperforms both LRU and CLOCK. Like ARC, Automobile is cocky-tuning and requires no user-specified magic parameters. Information technology uses 4 doubly linked lists: 2 clocks T1 and T2 and two simple LRU lists B1 and B2. T1 clock stores pages based on "recency" or "short term utility" whereas T2 stores pages with "frequency" or "long term utility". T1 and T2 incorporate those pages that are in the cache, while B1 and B2 comprise pages that take recently been evicted from T1 and T2 respectively. The algorithm tries to maintain the size of these lists B1≈T2 and B2≈T1. New pages are inserted in T1 or T2. If in that location is a striking in B1 size of T1 is increased and similarly if there is a hit in B2 size of T1 is decreased. The adaptation rule used has the same principle as that in ARC, invest more in lists that will give more hits when more pages are added to information technology.
Multi queue (MQ) [edit]
The multi queue algorithm or MQ was developed to improve the operation of second level buffer enshroud for e.g. a server buffer cache. It is introduced in a newspaper by Zhou, Philbin, and Li.[29] The MQ cache contains an grand number of LRU queues: Q0, Q1, ..., Q one thousand-1. Here, the value of m represents a hierarchy based on the lifetime of all blocks in that item queue. For example, if j>i, blocks in Q j will have a longer lifetime than those in Q i . In addition to these there is another history buffer Qout, a queue which maintains a list of all the Block Identifiers forth with their access frequencies. When Qout is full the oldest identifier is evicted. Blocks stay in the LRU queues for a given lifetime, which is defined dynamically past the MQ algorithm to be the maximum temporal distance betwixt two accesses to the same file or the number of cache blocks, whichever is larger. If a block has non been referenced inside its lifetime, it is demoted from Q i to Q i−1 or evicted from the cache if it is in Q0. Each queue also has a maximum access count; if a cake in queue Q i is accessed more than than 2 i times, this block is promoted to Q i+1 until it is accessed more than ii i+one times or its lifetime expires. Within a given queue, blocks are ranked past the recency of admission, according to LRU.[thirty]

We can see from Fig. how the m LRU queues are placed in the cache. Also run across from Fig. how the Qout stores the block identifiers and their corresponding access frequencies. a was placed in Q0 as it was accessed only once recently and we can cheque in Qout how b and c were placed in Q1 and Qii respectively equally their access frequencies are ii and iv. The queue in which a block is placed is dependent on access frequency(f) equally log2(f). When the cache is full, the first cake to be evicted volition be the head of Q0 in this case a. If a is accessed ane more than time information technology will movement to Qi below b.
Pannier: Container-based caching algorithm for chemical compound objects [edit]
Pannier[31] is a container-based flash caching machinery that identifies divergent (heterogeneous) containers where blocks held therein have highly varying access patterns. Pannier uses a priority-queue based survival queue structure to rank the containers based on their survival time, which is proportional to the live data in the container. Pannier is built based on Segmented LRU (S2LRU), which segregates hot and cold information. Pannier also uses a multi-footstep feedback controller to throttle flash writes to ensure flash lifespan.
Run across besides [edit]
- Cache-oblivious algorithm
- Locality of reference
- Distributed enshroud
References [edit]
- ^ a b Alan Jay Smith. "Design of CPU Enshroud Memories". Proc. IEEE TENCON, 1987. [1]
- ^ Paul Five. Bolotoff. "Functional Principles of Enshroud Memory" Archived 14 March 2012 at the Wayback Auto. 2007.
- ^ ARM Cortex-R Series Programmer's Guide
- ^ An Efficient Simulation Algorithm for Cache of Random Replacement Policy [2]
- ^ Johnson, Theodore; Shasha, Dennis (12 September 1994). "2Q: A Low Overhead High Performance Buffer Management Replacement Algorithm" (PDF). Proceedings of the 20th International Conference on Very Big Data Bases. VLDB '94. San Francisco, CA: Morgan Kaufmann Publishers Inc.: 439–450. ISBN978-1-55860-153-half-dozen. S2CID 6259428.
- ^ O'Neil, Elizabeth J.; O'Neil, Patrick E.; Weikum, Gerhard (1993). The LRU-One thousand Page Replacement Algorithm for Database Deejay Buffering. Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data. SIGMOD '93. New York, NY, United states of america: ACM. pp. 297–306. CiteSeerXx.1.i.102.8240. doi:10.1145/170035.170081. ISBN978-0-89791-592-2. S2CID 207177617.
- ^ Bilal, Muhammad; et al. (2017). "Time Aware Least Contempo Used (TLRU) Enshroud Management Policy in ICN". IEEE 16th International Conference on Advanced Communication Technology (ICACT): 528–532. arXiv:1801.00390. Bibcode:2018arXiv180100390B. doi:10.1109/ICACT.2014.6779016. ISBN978-89-968650-3-ii. S2CID 830503.
- ^ Hong-Tai Chou and David J. DeWitt. An Evaluation of Buffer Management Strategies for Relational Database Systems. VLDB, 1985.
- ^ Shaul Dar, Michael J. Franklin, Björn Þór Jónsson, Divesh Srivastava, and Michael Tan. Semantic Information Caching and Replacement. VLDB, 1996.
- ^ Ramakrishna Karedla, J. Spencer Love, and Bradley M. Wherry. Caching Strategies to Meliorate Disk Organisation Performance. In Calculator, 1994.
- ^ Jiang, Vocal; Chen, Feng; Zhang, Xiaodong (2005). "CLOCK-Pro: An Constructive Improvement of the CLOCK Replacement" (PDF). Proceedings of the Annual Conference on USENIX Annual Technical Conference. USENIX Clan: 323–336.
- ^ "Linux Memory Direction: Page Replacement Blueprint". 30 December 2017. Retrieved 30 June 2020.
- ^ "A CLOCK-Pro folio replacement implementation". LWN.net. 16 August 2005. Retrieved xxx June 2020.
- ^ Bilal, Muhammad; et al. (2017). "A Cache Direction Scheme for Efficient Content Eviction and Replication in Cache Networks". IEEE Access. 5: 1692–1701. arXiv:1702.04078. Bibcode:2017arXiv170204078B. doi:10.1109/Admission.2017.2669344. S2CID 14517299.
- ^ Jayarekha, P.; Nair, T (2010). "An Adaptive Dynamic Replacement Arroyo for a Multicast based Popularity Enlightened Prefix Cache Memory System". arXiv:1001.4135 [cs.MM].
- ^ a b Jain, Akanksha; Lin, Calvin (June 2016). "Dorsum to the Time to come: Leveraging Belady'south Algorithm for Improved Cache Replacement". 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA): 78–89. doi:10.1109/ISCA.2016.17.
- ^ a b Jaleel, Aamer; Theobald, Kevin B.; Steely, Simon C.; Emer, Joel (xix June 2010). "Loftier functioning enshroud replacement using re-reference interval prediction (RRIP)". Proceedings of the 37th annual international symposium on Reckoner architecture. ISCA '10. New York, NY, The states: Association for Calculating Machinery: 60–71. doi:10.1145/1815961.1815971. ISBN978-1-4503-0053-seven.
- ^ Qureshi, Moinuddin K.; Jaleel, Aamer; Patt, Yale N.; Steely, Simon C.; Emer, Joel (nine June 2007). "Adaptive insertion policies for high performance caching". ACM SIGARCH Computer Compages News. 35 (two): 381–391. doi:ten.1145/1273440.1250709. ISSN 0163-5964.
- ^ "THE 2d Enshroud REPLACEMENT CHAMPIONSHIP – Co-located with ISCA June 2017". crc2.ece.tamu.edu . Retrieved 24 March 2022.
- ^ Jain, Akanksha; Lin, Calvin (June 2018). "Rethinking Belady's Algorithm to Accommodate Prefetching". 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA): 110–123. doi:10.1109/ISCA.2018.00020.
- ^ Shah, Ishan; Jain, Akanksha; Lin, Calvin (April 2022). "Effective Mimicry of Belady's MIN Policy". HPCA.
- ^ Sutton, Richard S. (1 August 1988). "Learning to predict by the methods of temporal differences". Car Learning. 3 (1): 9–44. doi:10.1007/BF00115009. ISSN 1573-0565.
- ^ Liu, Evan; Hashemi, Milad; Swersky, Kevin; Ranganathan, Parthasarathy; Ahn, Junwhan (21 November 2020). "An False Learning Arroyo for Cache Replacement". International Conference on Machine Learning. PMLR: 6237–6247.
- ^ Jiménez, Daniel A.; Teran, Elvira (fourteen October 2017). "Multiperspective reuse prediction". Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture. New York, NY, United states: ACM. doi:ten.1145/3123939.3123942.
- ^ Jiang, Song; Zhang, Xiaodong (June 2002). "LIRS: an efficient low inter-reference recency fix replacement to meliorate buffer cache performance" (PDF). Proceedings of the 2002 ACM SIGMETRICS International Conference on Measurement and Modeling of Reckoner Systems. Clan for Computing Machinery. thirty (1): 31–42. doi:10.1145/511399.511340. ISSN 0163-5999.
- ^ Nimrod Megiddo and Dharmendra Southward. Modha. ARC: A Cocky-Tuning, Low Overhead Replacement Enshroud. FAST, 2003.
- ^ "Some insight into the read cache of ZFS - or: The ARC - c0t0d0s0.org". Archived from the original on 24 February 2009.
- ^ Danny Berend, Shlomi Dolev and Marina Kogan-Sadetsky. AdaptiveClimb: adaptive policy for enshroud replacement. SYSTOR, 2019.
- ^ Yuanyuan Zhou, James Philbin, and Kai Li. The Multi-Queue Replacement Algorithm for Second Level Buffer Caches. USENIX, 2002.
- ^ Eduardo Pinheiro, Ricardo Bianchini, Energy conservation techniques for disk array-based servers, Proceedings of the 18th annual international conference on Supercomputing, June 26-July 01, 2004, Malo, French republic
- ^ Cheng Li, Philip Shilane, Fred Douglis and Grant Wallace. Pannier: A Container-based Flash Enshroud for Compound Objects. ACM/IFIP/USENIX Middleware, 2015.
External links [edit]
- Definitions of diverse cache algorithms
- Caching algorithm for flash/SSDs
Source: https://en.wikipedia.org/wiki/Cache_replacement_policies
0 Response to "what other block replacement technique can be used and is proved to be the ideal"
Post a Comment